Micro Frontends at Dunelm
This article will focus on the technical implementation of Micro Frontends on dunelm.com. We won’t cover the basic concepts of what is an MFE (Micro Frontend) or the different types of MFE as I don't want to take credit for others' work. If you are looking to understand more about the basics of MFE, there are some great articles that do much more justice than I am capable of. For inspiration, please look here:
The Issues
Let's start with the issues we are facing. These can be summed up as a legacy, slow, monolithic architecture that we struggle to release new features to and tackle technical debt on. Due to this being a large site, the cognitive complexity is huge, so day-to-day development is becoming much harder and we would be approaching the dreaded rebuild in a couple of years.
Slow deployments: As the project increased in size, so did the number of unit, integration, and e2e tests along with time to lint, type checking, build process, etc... This means that the time to run these increased leading to longer pipelines and deployments.
Hard to identify issues: As the project grows, the complexity also grows and it is harder to have a clearly defined separation of concerns (especially with things such as a global Redux store). This increases the cognitive complexity meaning that developing the project introduces more side effects leading to more issues that are harder to identify.
Hard to adopt new best practices and tackle tech debt: With a lot of frontend projects, we end up with a monolith, and over time things get coupled and harder to decouple as the project grows and features are added, leading to more technical debt and patterns that often take a lot of rework to remove.
Cognitive complexity: As this is a large site with features being regularly added, it is hard to create boundaries between code, especially as domain knowledge leaves the company and new engineers join. This results in more cognitive complexity as new engineers try to understand multiple moving parts in one place.
Limited experimentation: When we cache pages, we fill up the cache slots for each page. One of the limitations we have with our current provider was that there are 250 of these. These quickly fill up when you have 15 flags which on an enterprise site is not many (15² = 225).
What We Were Aiming For
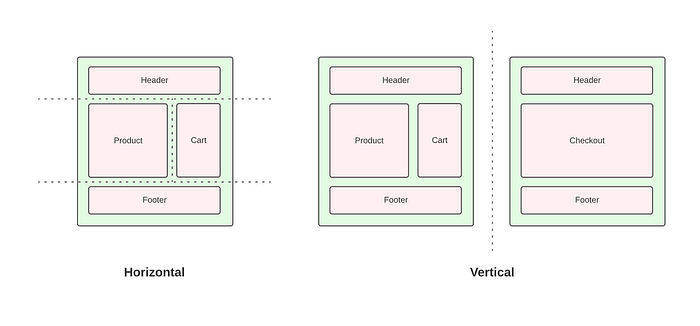
At a high level, the sort of MFE we were trying to implement looked like this:

As you can see it contains an aggregator (this is fronted by a CDN but only for feature flagging more on this later, nothing actually gets cached here). Then we have the fragments which are all fronted by our CDN and the cache configured independently. This allows us to get an accumulated cache which makes our site much faster than having independently cached pages. This is because the horizontal fragments create this accumulated cache for the pages and this effect is multiplied across multiple pages - for example, the header can be cached for multiple pages and for much longer than the product prices.

At a lower level, you can see how this interacts with the fragments. This allows us to use different technologies for each of the fragments and even go after different implementations, such as you can see some use SSG (server-side generation) and or static components and are stored in s3 buckets whereas others use SSR (server-side rendering) with Lambdas. This implementation allows both vertical and horizontal slicing (both page slices and fragments within a page).
This also allows us to deploy and test vertical slices (backend and frontend together) easily as we have a neat separation of concerns with fragments being able to be tested in isolation and as part of the larger system (more on this later).
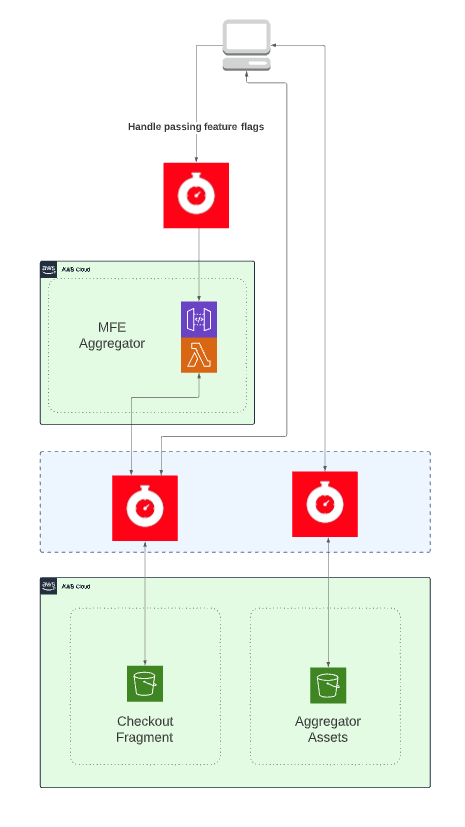
At a low level, you can see all we are doing is using a flag to split the traffic towards are new MFE. Then the aggregator is responsible for generating the page and any other request goes directly to the CDN that fronts the assets —we use the same domain with an additional URL path set in the CDN to achieve this.
This allows us to only deploy the new fragment, therefore, only running the tests, lining, and build steps needed for that fragment resulting in faster deployments. It also means that because we are only serving the content needed that will already be cached at the fragment lever we have a faster site.
We do this by versioning the buckets and APIs for blue-green deployments and canary releases. This also means that we are able to test multiple versions of the site just by building two versions and using a feature flag to split test, meaning no degradation by removing caching or anything like that. We also use this for testing (more on this next).
Tools and Development
As MFE is a fairly new concept, there are a couple of tools but nothing concrete, so we decided to go for an in-house solution. We spent a lot of time weighing up things like single spa, Project Mosaic, Frint, and OpenComponets but at the time of starting this project, these had rudimentary support or did not support SSR. We did also not want to couple ourselves with a heavy all-encompassing framework that might be obsolete in a couple of years (as is the js framework way).
What we chose to do is use s3 buckets to hold our fragments or lambda’s where necessary. These are frontend directly by fastly and serve their assets and content. This means that each fragment is completely independent and responsible for its own assets. How do we share common libs I hear you ask? We use shared modules in the webpack config, but we are moving to the module federation. It is also worth mentioning that we use learna for sharing modules between stacks. At the time of building, this next.js did not support module federation we are currently investigating how to make this work.
We are using bit.dev for our component library — this allows us to easily share components between the different fragments. The other cool thing that bit.dev does is allow us to version our components so that we do not have to update all fragments at once. This means that we gain massive confidence in any component changes only trading of marginal duplication for this.
For state management, we will use a simple event system to pass notifications from fragment to fragment. This can later be evolved to something like RxJs and allows our fragments to manage state however they see fit, whether this is with context, zustand, or other state management that the team thinks is most comfortable.
Currently, we have a react site and for the SSR from the aggregator, we are using next.js. This allows us to have a standardized way of seeing pages along with relying on a framework and not having to reinvent the wheel and leverage great documentation. One of the main choices for this was the routing — this allows us to keep the seamless SPA like experience as we add new fragments by hijacking or exposing the router to the rest of the app and just utilizing their SSR implementation.
Testing & Local environments
Local development has been much improved as you only need to run the fragment you are developing on. Therefore, if there is an issue with API in another part of the site or a bug/error, simply just spin up your section and continue development. It also means development envs can be faster as they are not doing as much.
It does mean that you will occasionally need to run the whole site together in a local env may be for exploratory testing before merging to the trunk or for working on a ticket. To do this for fragments, we allow the fragment to be pushed up to s3 with a new version as we discussed earlier and use a cookie to point the aggregator in this version. We create a new volatile build for the aggregator and point to the fragments. The same applies to integration and E2E testing.
This allows us to do both vertical and horizontal slices with the templating system we designed inside the next app.
All of this combined with only running the integration/E2E, reduced lining, and reduced build time resulted in a reduction by more than half of the time to prod. A reduction in the pipeline time of 57.5 to be precise and there is still lots of room for improvement.
Rollout and Results
The rollout was pretty straightforward as we used a feature flag to move traffic from the old site to the new. And because this sits on a new instance, we are able to easily track performance and roll out bug fixes.
One of the main advantages of this architecture is that it allows the teams to fully own the vertical slice deploying both the backend via our existing serverless architecture and now the frontend fragment without being blocked by other teams. This gives these squads total ownership of what they are deploying.
This was successful and actually resulted in a 3rd faster page loading times, with this just applied to checkout we saw an uplift of 6% in conversion rate. The exact results are as follows:
- 6.11% uplift in “Basket to Checkout %” (This is the most reliable final number to quantify the headline impact of MFE)
- 5.58% uplift in “Basket to Payment %”
- 5.67% uplift in “Basket to Success%”
Conclusion
Slow deployments — these were reduced by 60%
Hard to identify issues — the newly created separation of concerns has helped boost ownership and visibility.
Hard to adopt new best practices — less coupled code/deployments and fragment architecture now allow us to easily adopt new technologies.
Cognitive complexity — this will reduce massively now we better encapsulation.
Limited experimentation — we are now on our way to having a much better flagging system being able to test different versions of a build.
The added bonus of a much faster site.
Looking forward: We are very new on this journey only moving a couple of sections of the site to fragments. We are also investigating moving the aggregator to edge computing… so please stay tuned for more updates ;)

